So I have this architecture where we have 2 separate Kubernetes clusters. The first cluster runs in GKE, the second on ‘the beast of the basement‘ (and then there’s a bunch in AKS but they are for different purposes). I run Gitlab-runner on these 2 Kubernetes clusters. But… trouble is brewing.
You see, runners are not sticky. And, you have multiple stages that might need to share info. There are 2 methods built-in to gitlab-runner to use, 1 is the ‘cache’ and 1 is ‘artifacts’. The general workflow is ‘build… test… save… deploy…’. But ‘test’ has multiple parallel phases (SAST, Unit, DAST, System, Sanitisers, …).
So right now I’m using this pattern:
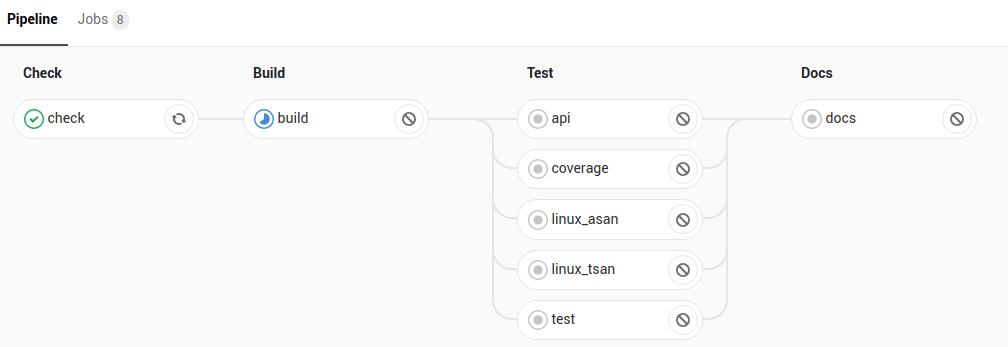
But a problem creeps in if ‘build’ runs on a different cluster than ‘linux_asan’. Currently I use the ‘cache’ (courtesy of minio) to save the build data to bootstrap the other phases. For this particular pipeline, if the cache is empty, each of the test phases works, at reduced efficiency.
However, I have other pipelines where the ‘build’ stage creates a docker image. In this case, the cache holds ‘docker save’ and the pre- script runs ‘docker load’ (using DinD). When the subsequent stages run on a different cluster, they actually fail instead.
So… Solutions.
- Run a single cache (in GKE). Both clusters use it. All works, but the performance of cache-upload from the 2nd cluster is poor
- Delete the GKE cluster gitlab-runner entirely
- Figure out a hierarchical-cache using ATS or Squid
- Use the ‘registry’, on build, push w/ some random tag, after test fix the tag
- Use the ‘artifacts’ for this. Its suffers from the same cache-upload speed issue
- Go back to the original issue that cause the deployment of the self-run Kubernetes cluster and find a cost-economical way to have large build machines dynamically (I tried Azure virtual kubelet but they are nowhere close to big enough, I tried Google Builder but its very complex to insert into this pipeline).
Others?
The problem is the basement-machine has 1Gbps downstream, but only 50Mbps upstream. And some of these cache items are multi-GiB.
Leave a Reply