Tag: security
When managed software goes bad… A cloud tale
So the other day I wrote of my experience with the first ‘critical’ kubernetes bug, and how the mitigation took down my Google Kubernetes (GKE). In that case, Google pushed an upgrade, and missed something with the Calico migration (Calico had been installed by them as well, nothing had been changed by me). Ooops. Today,…

Canadian National Cyber Threat Assessment
Or perhaps you were too busy buying i-Tunes cards to pay off that CRA debt you didn’t know you had? (hint: there is never a reason to do this!) I’m a bit focused these days on p19 (supply chain process), but you might be more interested in p22 (critical infrastructure). But I’m intrigued by the…
Suicidal clouds cause consternation
Another day another piece of infrastructure cowardly craps out. Today it was Google GKE. It updated itself to 1.11.3-gke.18, and then had this to say (while nothing was working, all pods were stuck in Creating, and the Nodes would not come online since the CNI failed). 2018-12-03 21:10:57.996 [ERROR][12] migrate.go 884: Unable to store the…
Supply chain risk: more javascript npm shenanigans, OSS governance
Lately I’ve been talking a lot about the supply chain risk. You import some software, and are suddenly importing their business model and practices. Well, we’ve just had another ‘shenanigan’ unveiled. And its got some good drama. https://github.com/dominictarr/event-stream/issues/116 In a nutshell there is some package which is relatively stable. The original developer doesn’t use it anymore,…
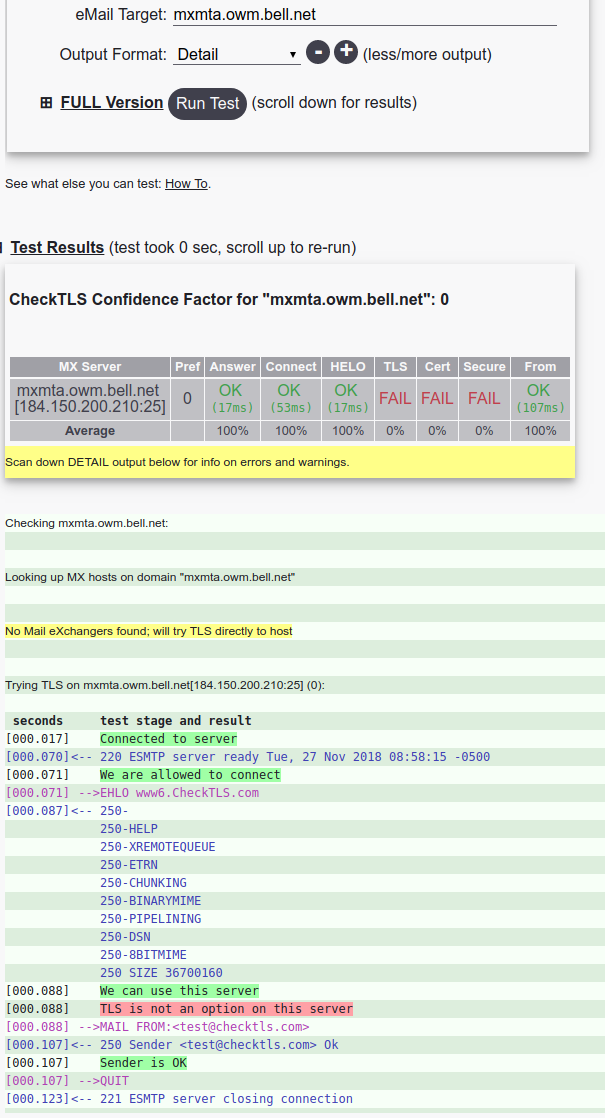
Why does Bell Canada not allow encrypting your email in transit?
Hint: you want your email to be encrypted in transit. Now, lets take a look at some stats. From my earlier post about ‘Why is Canada less encrypted than the US‘?, and from Google’s Transparency Report, we dig into Sympatico. This is Bell Canada‘s brand for Internet. We see that there is no encrypted email exchanged…