Tag: agile
Suicidal clouds cause consternation
Another day another piece of infrastructure cowardly craps out. Today it was Google GKE. It updated itself to 1.11.3-gke.18, and then had this to say (while nothing was working, all pods were stuck in Creating, and the Nodes would not come online since the CNI failed). 2018-12-03 21:10:57.996 [ERROR][12] migrate.go 884: Unable to store the…

Next Chautauqua: Continuous Integration!
Tomorrow (Tues 27, 2018) we’re going to have the next meetup to talk Continuous Integration. Got a burning desire to rant about the flakiness of an infinite number of shell scripts bundled into a container and shipped to a remote agent that is more or less busy at different hours? Wondering if its better to use…
Separate CI cluster woes: can hierarchical caching help?
So I have this architecture where we have 2 separate Kubernetes clusters. The first cluster runs in GKE, the second on ‘the beast of the basement‘ (and then there’s a bunch in AKS but they are for different purposes). I run Gitlab-runner on these 2 Kubernetes clusters. But… trouble is brewing. You see, runners are…
CI’s Gone Wild: Totally Tenacious Test Tuning
So one of the upstream projects I am working on has added some new tests. Should be a good thing, right? Suddenly, out of nowhere, we start getting ‘terminated 137’ on CI stages. The obscure unix math is… substract 128 to get the signal. So kill -9 (see here for why, tl;dr: 8-bit, 0-128==normal return,…
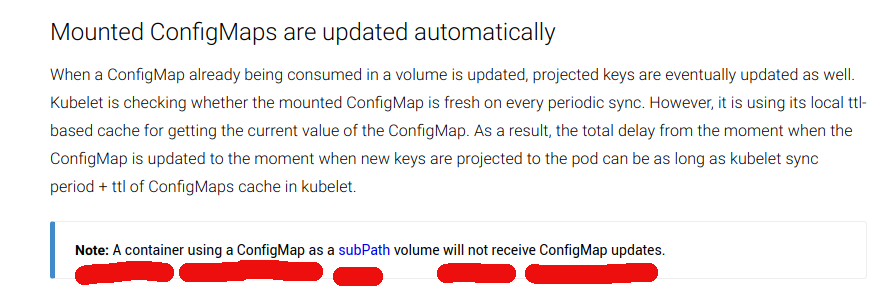
Kubernetes volume-mounts with subPath and inotify. Bah humbug
So. I’ve been working on this tool ‘fluent-bit‘. You know the drill. Compile, curse, change, pull-request, repeat. And one of the features I added was to auto-watch its config file and restart on change. This is important in a Kubernetes environment since you supply config via a ‘config map’, and expect it to auto-apply. Great.…