 An evolution is well underway in IT architectures. In the early days, the number of computers were small (and they were in special rooms with physical security). As applications moved out to smaller servers, they stayed in these data centres, and complex network rules (firewalls etc) were deployed to control access to the *machine*. Sets of like machines were on adjacent IP ranges (called subnets), and these network rules dealt with subnets. Scaling (adding servers) was a manual task, and, since the subnets stayed the same, didn’t usually require firewall reconfiguration.
An evolution is well underway in IT architectures. In the early days, the number of computers were small (and they were in special rooms with physical security). As applications moved out to smaller servers, they stayed in these data centres, and complex network rules (firewalls etc) were deployed to control access to the *machine*. Sets of like machines were on adjacent IP ranges (called subnets), and these network rules dealt with subnets. Scaling (adding servers) was a manual task, and, since the subnets stayed the same, didn’t usually require firewall reconfiguration.
In the last years, this style has fallen out of favour in 4 key areas:
- The ‘machines’ are now in a shared data centre (and usually shared themself, e.g. public cloud)
- The IP ranges are not contiguous (your IP’s and your neighbours are co-mingled)
- Scaling in and out (and deployment) is now done by software, not people
- Applications are now decomposed into many small services each of which has a ‘machine’ and an ‘IP’.
As a consequence of these decisions, risk is not only increasing, but has become more difficult to quantify. Who really knows how that ‘magic deployment software’ works? New risks (e.g. Spectre) magnify shared hosting risks.
So, lets take an example stroll through what can happen. I’ll use everyone’s favourite search engine, shodan.io. Lets talk about a specific cloud ‘engine’, Kubernetes, and how one set of companies have used it and exposed information.
So, lets dive down the rabbit hole. First, lets search for Kubernetes and http:200. One of the IP that comes back is http://34.227.255.62/, an IP address in Amazon AWS. If we open that in a browser, we get some clues:
{"_links":{"dashboard":{"href":"http://34.227.255.62/dashboard"},"streams/definitions":
{"href":"http://34.227.255.62/streams/definitions"},"streams/definitions/definition":
{"href":"http://34.227.255.62/streams/definitions/{name}","templated":true},"streams/deployments":
{"href":"http://34.227.255.62/streams/deployments"},"streams/deployments/deployment":
{"href":"http://34.227.255.62/streams/deployments/{name}","templated":true},"runtime/apps":{"href":"http://34.227.255.62/runtime/apps"},"runtime/apps/app":
{"href":"http://34.227.255.62/runtime/apps/{appId}","templated":true},"runtime/apps/instances":
{"href":"http://34.227.255.62/runtime/apps/interface%20org.springframework.web.util.UriComponents%24UriTemplateVariables/instances"},"metrics/streams":
{"href":"http://34.227.255.62/metrics/streams"},"tasks/definitions":{"href":"http://34.227.255.62/tasks/definitions"},"tasks/definitions/definition":
{"href":"http://34.227.255.62/tasks/definitions/{name}","templated":true},"tasks/executions":
{"href":"http://34.227.255.62/tasks/executions"},"tasks/executions/name":{"href":"http://34.227.255.62/tasks/executions{?
name}","templated":true},"tasks/executions/execution":{"href":"http://34.227.255.62/tasks/executions/{id}","templated":true},"jobs/executions":
{"href":"http://34.227.255.62/jobs/executions"},"jobs/executions/name":{"href":"http://34.227.255.62/jobs/executions{?
name}","templated":true},"jobs/executions/execution":{"href":"http://34.227.255.62/jobs/executions/{id}","templated":true},"jobs/executions/execution/steps":
{"href":"http://34.227.255.62/jobs/executions/{jobExecutionId}/steps","templated":true},"jobs/executions/execution/steps/step":
{"href":"http://34.227.255.62/jobs/executions/{jobExecutionId}/steps/{stepId}","templated":true},"jobs/executions/execution/steps/step/progress":
{"href":"http://34.227.255.62/jobs/executions/{jobExecutionId}/steps/{stepId}/progress","templated":true},"jobs/instances/name":
{"href":"http://34.227.255.62/jobs/instances{?name}","templated":true},"jobs/instances/instance":
{"href":"http://34.227.255.62/jobs/instances/{id}","templated":true},"tools/parseTaskTextToGraph":
{"href":"http://34.227.255.62/tools"},"tools/convertTaskGraphToText":{"href":"http://34.227.255.62/tools"},"apps":
{"href":"http://34.227.255.62/apps"},"about":{"href":"http://34.227.255.62/about"},"completions/stream":{"href":"http://34.227.255.62/completions/stream{?
start,detailLevel}","templated":true},"completions/task":{"href":"http://34.227.255.62/completions/task{?
start,detailLevel}","templated":true}},"api.revision":14}OK, seems like a lot of JSON gibberish right? But lets explore one of the endpoints. Lets start with dashboard.
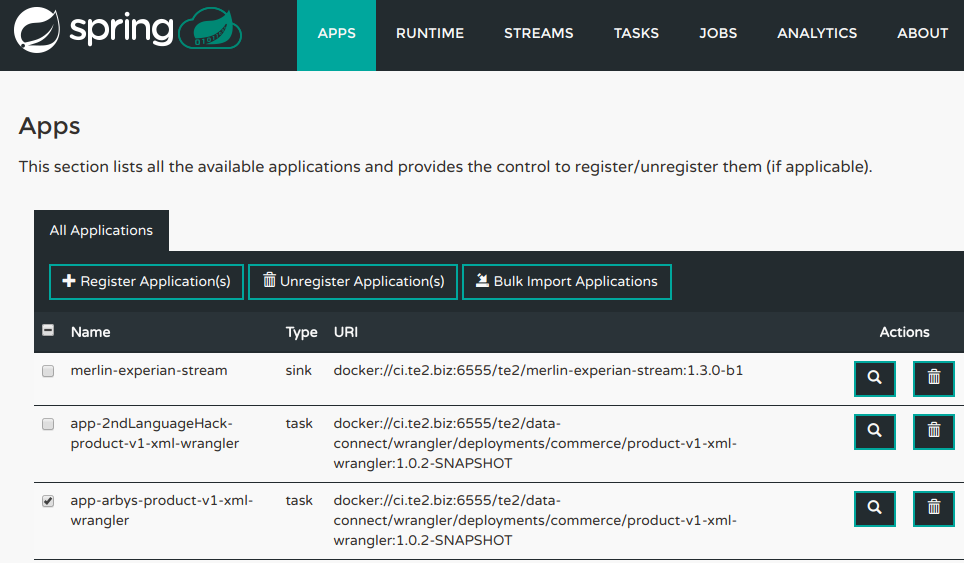 Note there was no ask for a password. We are just in. From here we can see some information. The names of companies (Arbys, Hilton, Happyland, etc.) We can see some specific reports (Merlin ride wait times, show times, etc). We can see it for certain geographies (EU, US).
Note there was no ask for a password. We are just in. From here we can see some information. The names of companies (Arbys, Hilton, Happyland, etc.) We can see some specific reports (Merlin ride wait times, show times, etc). We can see it for certain geographies (EU, US).
And, we can see that there are in turn some business relationships in there (Merlin <-> Experian). Perhaps related to Exerian’s “email list of over 27 million… expertise in data collection”.
The ‘applications’ listed on this page are in turn URL’s. Going back to the ‘service decomposition’, it suggests that they will be individually addressable, lets try. Seems like its a ‘jFrog Artifactory‘ for a company called TE2 (The Experience Engine). An ‘artifactory’ is a “everything beyond source code” dump of information. Great. It gives a login, does it accept ‘admin/admin’? No. Does it accept ‘admin/password’. Yes. Sigh. OK, i’m not going any further there.
The specific application this is a dashboard for is ‘Spring Cloud Data Flow‘. Its a real-time data processing pipeline: “Pipelines consist of Spring Boot apps, built using the Spring Cloud Stream or Spring Cloud Task microservice frameworks.”. Those ‘microservices’ are the decomposed applications above.
What mischief could we do with this dashboard? Well, it allows creating your own pipelines and workflow, I guess you could make one that tee’d the data to you somewhere else. Or modified it. Or created data.
OK enough of someone else’s misery, lets talk about how this happened. The most likely reasons are ‘very simple software hid a large amount of complexity’, allowing someone to deploy something complex without understanding its internals. And those internals being a vast set of ‘open’ things.
But first I digress. Early in my university career I remember a professor arguing that we should have to learn slide-rules since typing numbers into a calculator, you didn’t have to think, and could end up with nonsense you wouldn’t spot. We then had another professor who gave us a problem, a boat is held at 4 corners by ropes of 45 degrees, pushing forward with a certain force, calculate the tension in each rope. Now, some in the class turned around, assumed all ropes equal, did some sin(45degrees), divide by 4, and gave an answer. The professor angrily yelled, if I teach you nothing else, let me teach you you cannot push a rope. tl;dr engineering!
So, there is an argument to be made for ‘do it all by hand before you get to automate’ so you are forced to understand what talks to what, and how to secure. Sure, if you do this all the time you will then have human error creeping in. But maybe you have to build the sandbox by hand first?
What do you think? Does anyone want to follow those links more and see what is the best-selling Sandwich @ Arbys? Or find out of the Hilton info is keyed by date-of-birth and credit-card-number?
One thing for sure, the problem is not going away. Business moves faster, cloud is cheaper, DevOps reduces schedules, etc.
Leave a Reply