Tag: security

Do the phish scammers care more about your security than you do?
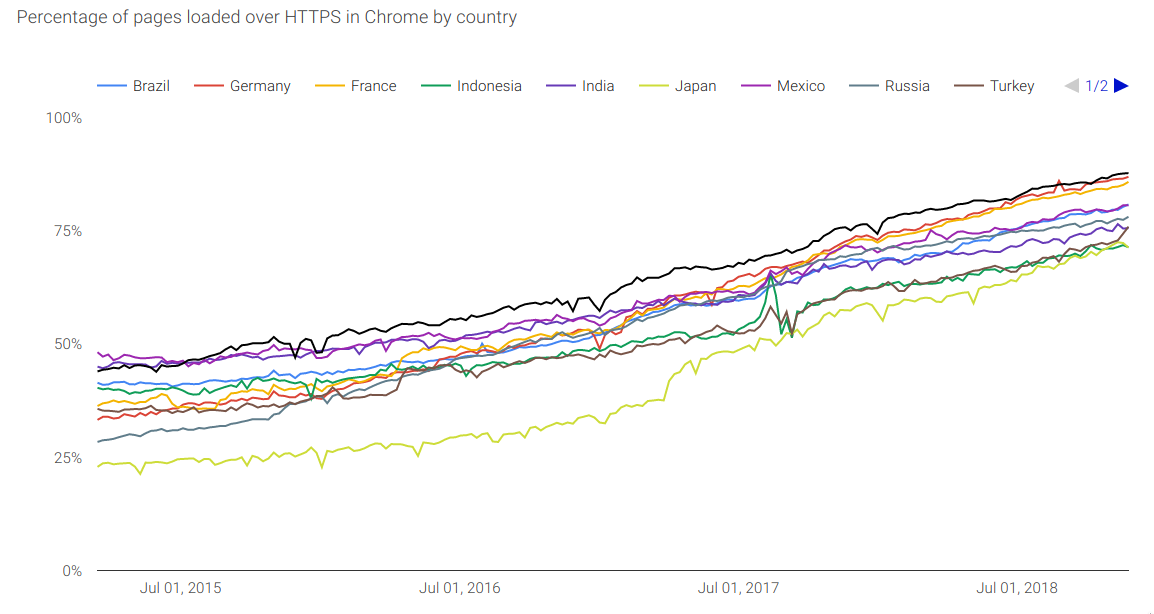
Phishing has hit the halfway point on encryption. This means that being TLS-encrypted is no indication a site is real or not (its an indication that it is exactly what it says it is, but not what it might appear as). Ironically, they might be stronger than the average web site. If we look at…
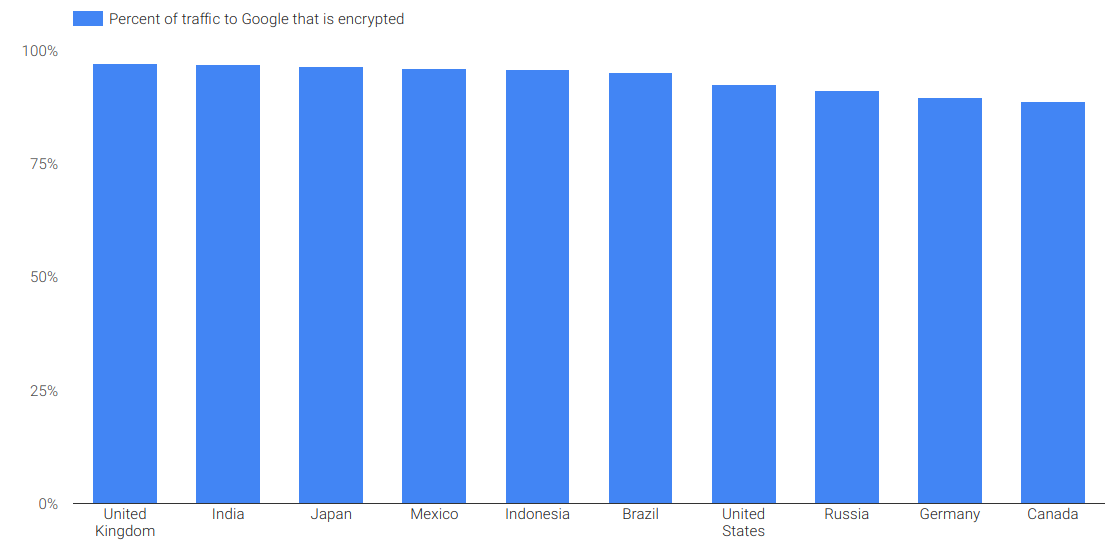
Why is Canada worse than the UK and US for encrypted web?
Courtesy of our friends @ Google and their Transparency Report we see that Canada is 89% encrypted to Google. Good, but not great when you realise the UK is 97% encrypted. What could drive this difference? I would think device-types and ages would be similar. This traffic is a bellwether of other encrypted traffic, and we…
Next Chautauqua: Continuous Integration!
Tomorrow (Tues 27, 2018) we’re going to have the next meetup to talk Continuous Integration. Got a burning desire to rant about the flakiness of an infinite number of shell scripts bundled into a container and shipped to a remote agent that is more or less busy at different hours? Wondering if its better to use…
Best Black Friday deal: Shodan membership for $5
Who wouldn’t want this? For $5 you get lifetime membership to everyone’s favourite search engine, Shodan. Buy early buy often, scan some internets today!
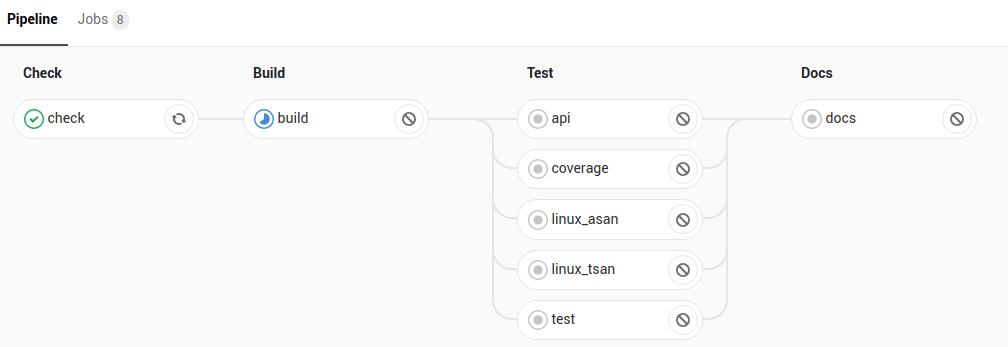
Separate CI cluster woes: can hierarchical caching help?
So I have this architecture where we have 2 separate Kubernetes clusters. The first cluster runs in GKE, the second on ‘the beast of the basement‘ (and then there’s a bunch in AKS but they are for different purposes). I run Gitlab-runner on these 2 Kubernetes clusters. But… trouble is brewing. You see, runners are…