Tag: continuous

Lessons from the cloud: it’s not fast: it’s wide
Starting to work w/ Azure. Go to create my first Kubernetes cluster. After 15 minutes of watching the slide dots in the web, I give up. I try the CLI, same deal. This must be just me right? Wrong. This is a general observation about cloud tooling. Things are very slow because of all the…
I’m picturing a museum with 4 billion exhibits
A museum is where you go to see old technology, now retired. The steam museum, etc. Let’s get together and create an IPv4 museum. It will have 2^32 exhibits. There will be Class-A halls, class-B halls, class-C halls. I’m not sure yet how to arrange the class-D hall, maybe its everywhere and nowhere at the…
Using Azure Container Instances to expand CI?
So Azure has a ‘serverless’ kubelet concept. In a nutshell we follow virtual-kubelet instructions (except they were missing az provider register –namespace ‘Microsoft.ContainerInstance’, pull request sent). What this does is schedule Pods (which have a special annotation) to a farm of servers which are willing to accept ‘foreign’ containers (Pods). This means your Kubernetes master delegates…
Navigating the restrictions of CI and Bazel
Working on a tool called ‘envoy‘. Its a proxy server that’s at the heart of Istio. And its build process is a tool called ‘Bazel‘. I’ve been having some battles with Bazel. First it ate my laptop (well not literally, but it uses more resources than the laptop has. The laptop has 2C4T w/ 16GB,…
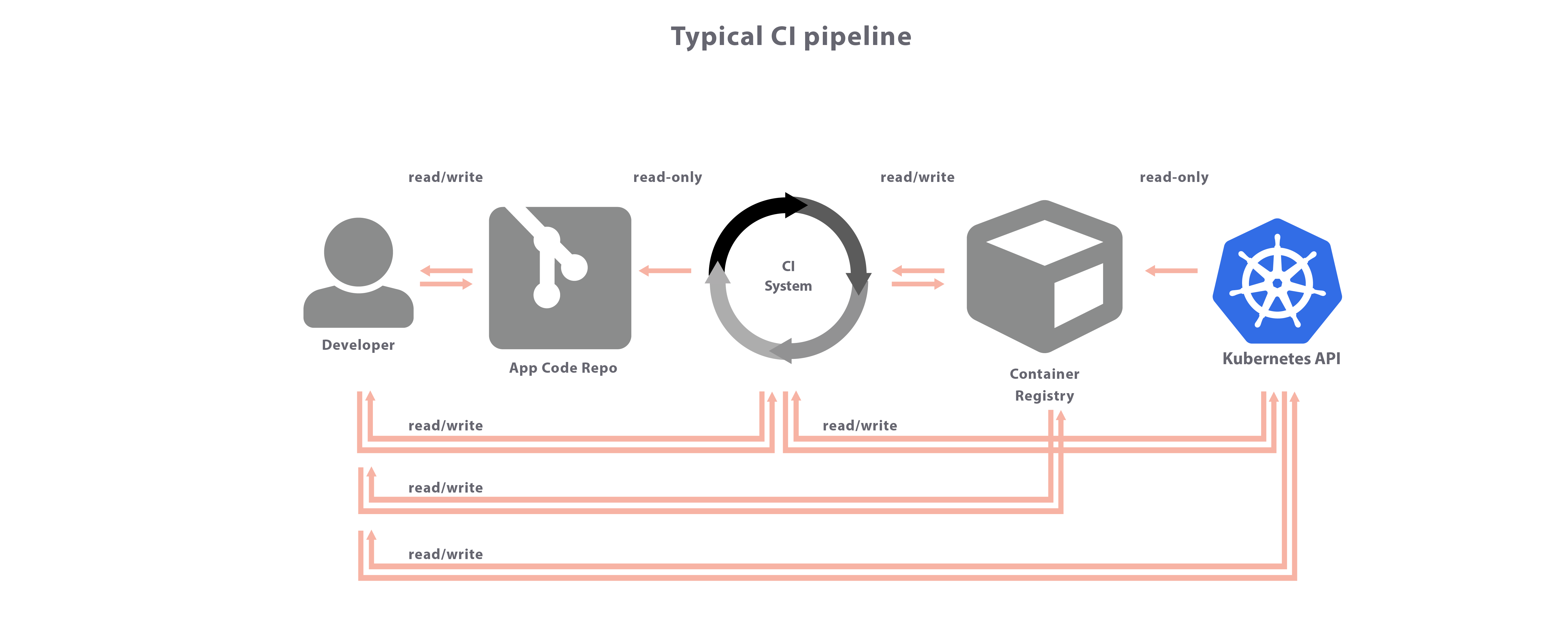
Should I use my CI pipeline to do continuous delivery? A controversy!
I’m using Gitlab, and one of the things they promote is Auto-Devops. In a nutshell, you use the Gitlab-CI as your means from start to finish, starting w/ an idea, through code, unit-test, address-space-tests, dynamic-tests, thread-tests, license-checks, lint, code-format, static scans, … all the way until it lands on a running server somewhere for your…