I’m using Gitlab, and one of the things they promote is Auto-Devops. In a nutshell, you use the Gitlab-CI as your means from start to finish, starting w/ an idea, through code, unit-test, address-space-tests, dynamic-tests, thread-tests, license-checks, lint, code-format, static scans, … all the way until it lands on a running server somewhere for your customers to get their grubby virtual fingers on it.
And I gotta say, it works really well.
Enter weave. They have a pattern ‘gitops‘. It has ‘git’ in the name so it must be good, right? They also have some opinions on whether a CI tool is good for continuous deployment. In short: NO:
Your CI server is not an orchestration tool. You need something that continually attempts to make progress (until there are no more diffs). CI fails when it encounters a difference. In combination with a human operator, a CI server can be made to force convergence, but this creates other issues. For example your CI scripts might not be able to enforce an idempotent and/or atomic group of changes.
They have coined the term ‘CIOps’ for the alternative, and they diagram it thusly:
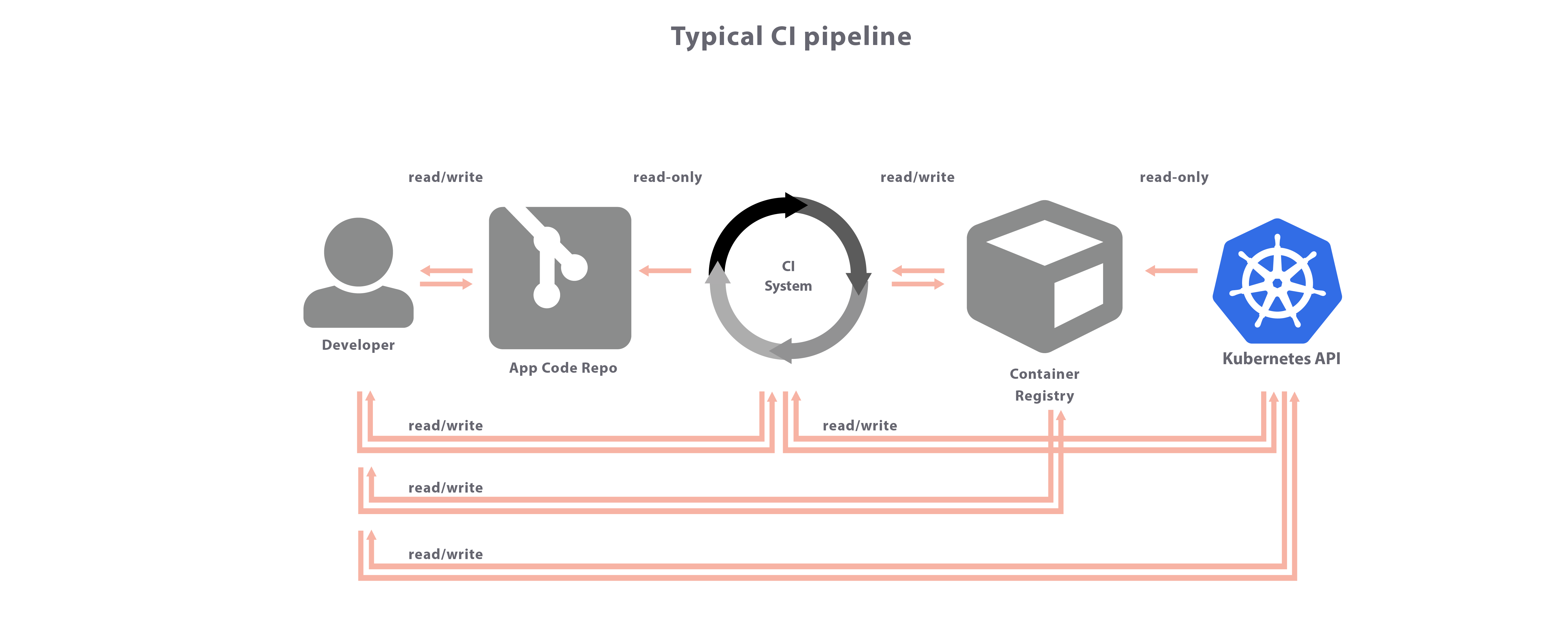
versus their product (gitops) which is thusly:
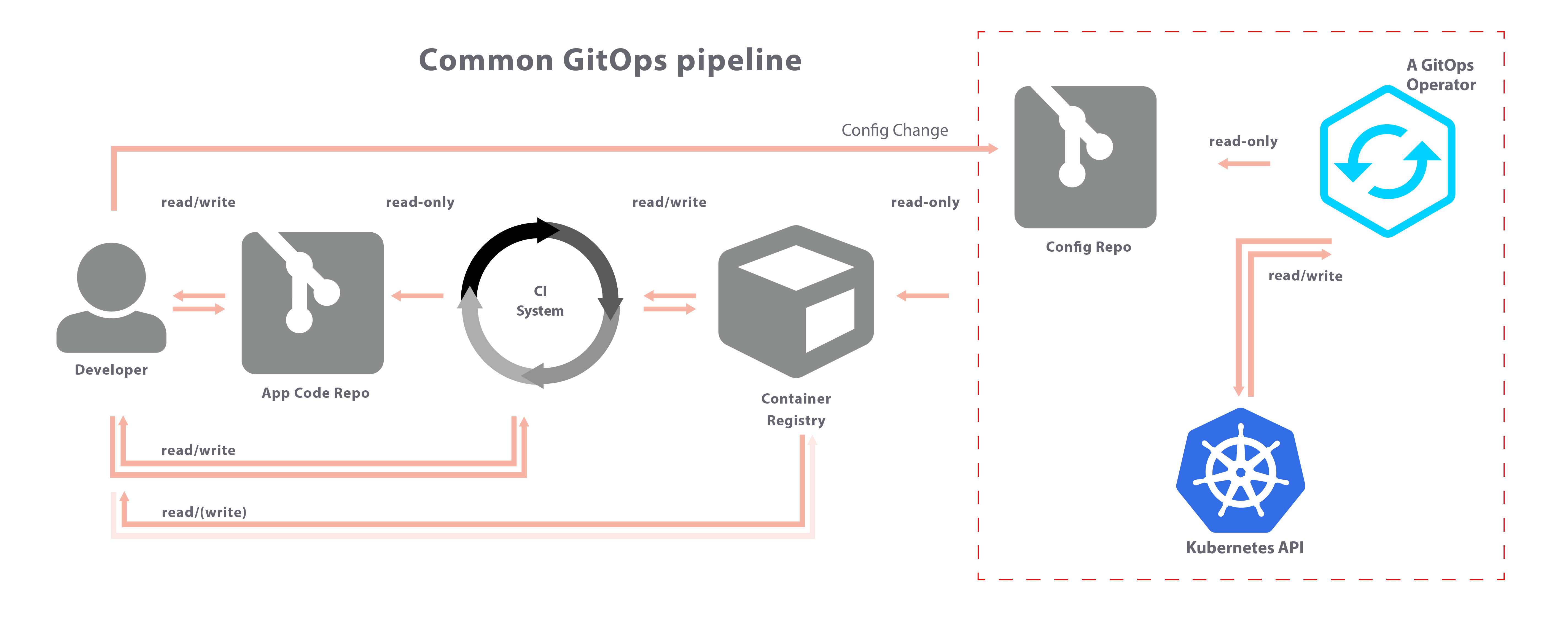
They don’t talk about gitlab-CI (which I think is stronger than the travis and circle ones they reference), its much better integrated to Kubernetes. Also, gitlab does monitoring where the others don’t. It also supports ‘environments’ (e.g. staging, dev, production).
So, gentle reader, any opinions on this?
Leave a Reply