Tag: agile

Dramatically simplify developing your app for Kubernetes: a sample
Apologies if this is old-hat for you, but, I was awfully tired of ‘git commit; git push; … wait for CI; … helm…’ Lets say you are developing a simple Python flask app. You are going to edit/push many times to get this going perfectly in Kubernetes. So many docker builds and pushes and redeploys…
Kooking Kontainers With Kubernetes: A Recipe for Dual-Stack Deliciousness
If you have a mild allergy to ascii or yaml you might want to avert your eyes. You’ve been warned. Now, lets imagine you have a largish server hanging around, not earning its keep. And on the other hand, you have a desire to run some CI pipelines on it, and think Kubernetes is the…
Pruning elastics with Kubernetes CronJobs
There was a time you just ran ‘crontab -e’ to make this happen. But, progress, are you still on my lawn? Lets discuss how to solve the specific issue of ‘my database fills up my disk’ in a Cloud Native way. So the situation. I’m using ElasticSearch and fluent-bit for some logging in a Kubernetes cluster.…
Increasing the usefulness of your Kubernetes Ingress logging
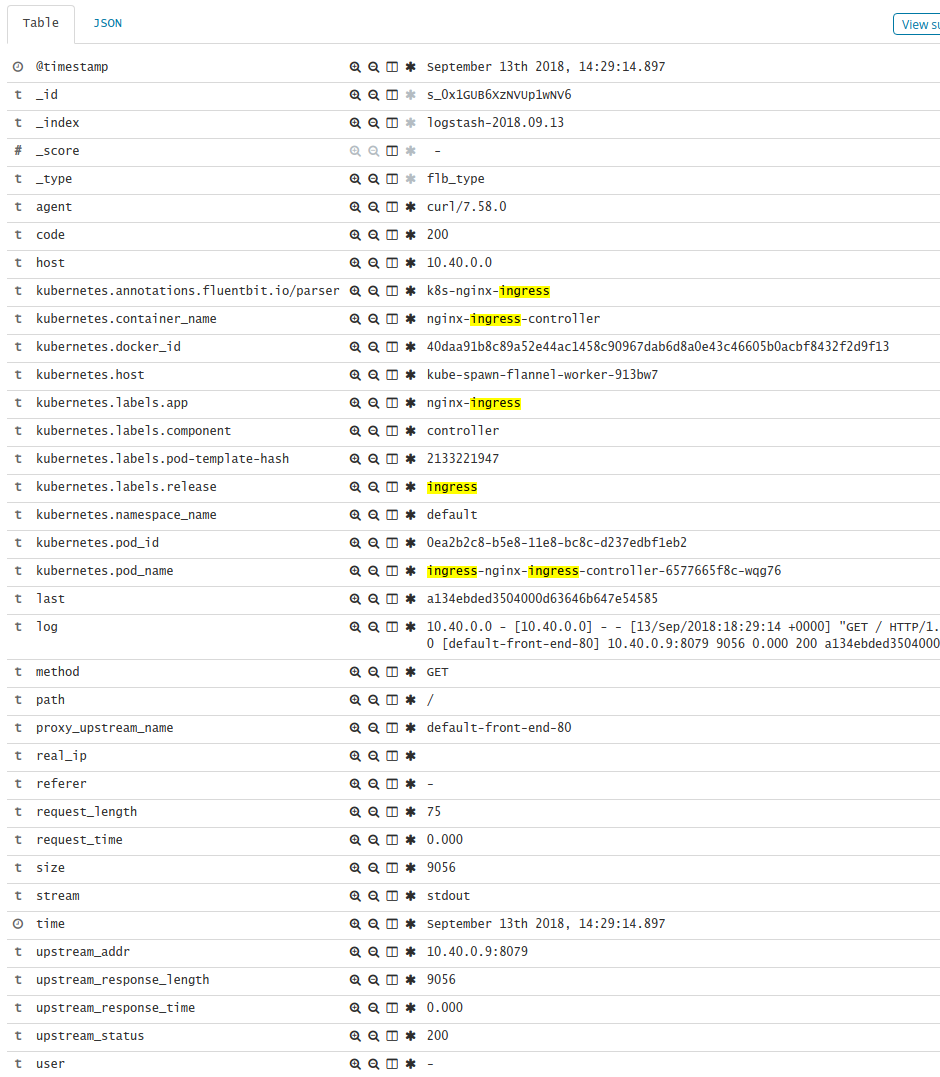
Like most cloud folks you are probably using Kibana + Elasticsearch as part of your log management solution. But did you know with a little regex-fu you can make that logging more interesting? See the kibana expansion in the image, the URI, host, service, etc are all expanded for your reporting pleasure. First, lets install…
How to avoid being logged, Kubernetes-style
So you have a K8S cluster. Its got a lovely Ingress controller courtesy of helm install stable/nginx-ingress. You’ve spent the last hours getting fluent-bit + elastic + kibana going (the EFK stack). Now you are confident, you slide the user-story to completed and tell all and sundry “well at least when you’re crappy code gets…