Tag: continuous

Lessons learned: COPY . and geometric size progression
So another day and another ‘registry out of space’. I wrote earlier about the crappy experience increasing this size (and GKE is still on 1.10 so I can’t use the 1.11+ resize mechanism!!!) Vowing not to repeat the ‘that can’t be the right method’ that I pioneered in that post, I decided to dig a…
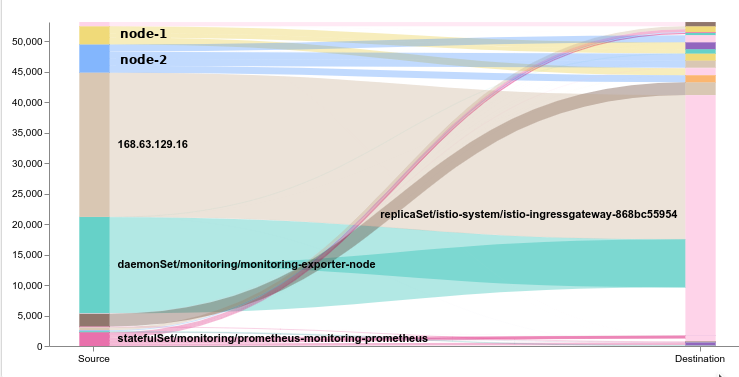
The case of the nosy neighbour: Azure is poking me!
We’ve all been there. Working to a deadline trying to get our e-commerce site going to make sure cats don’t get cold feet for the winter. And because its a microservices cloud jwt polyglot kubernetes istio [insert jargon here] world, well, its not as easy to debug. So many moving pieces. Remember when I said…
The quest for minimalism
Earlier I wrote about the ‘elastic-prune‘ a simple cron-job that lived in Kubernetes to clean up an Elasticsearch database. When I wrote it, I decided to give ‘distroless‘ a whirl. Why distroless? Some will say its because of size, they are searching for the last byte of free space (and thus speed of launching). But,…
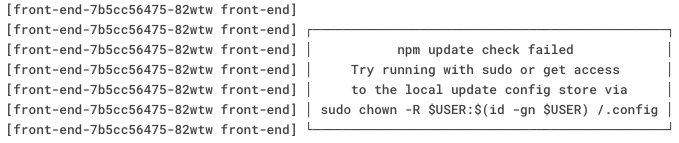
Misguided auto-updates in a container world
Let’s say one day you are casually browsing the logs of your giant Kubernetes cluster. You spot this log message: “npm update check failed”. Hmm. Fortunately you have an egress firewall enabled, blocking all outbound traffic other than to your well-known API’s, so you know why it failed. You now worry that maybe some of…
When good containers go bad: github issues are the new release notes
The world is getting faster with shorter cycle times. Software releases, once things that celebrated birthdays are now weekly. Emboldened by the seemingly bullet-proof nature of Kubernetes and Helm, and trying to resolve an issue with an errant log message, I update the nginx-controller. Its easy: helm upgrade nginx-ingress stable/nginx-ingress Moments later it is done.…