Tag: agile

Accessing a service in a different namespace from a single ingress in Kubernetes
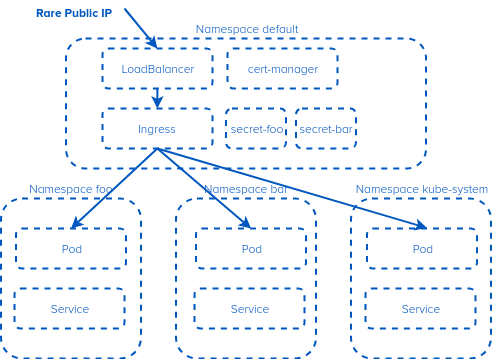
IPv4. Its rare when its public, and annoying when its private. So we try and conserve this precious resource. One of the things that makes it complex is Kubernetes namespaces. A Kubernetes Ingress controller is not namespace aware (you can’t have a shared Ingress that has services in multiple namespaces). Or can you? What if…
Azure Kubernetes Service (AKS): batteries not included
The difference between Azure AKS and Google GKE is stark. GKE just worked. Single sign on, login, create cluster. It walked me through a couple of questions (how many nodes, what size of node). A minute or so later it was done. Azure. Still working on it. Attempt 1. Use the web interface. Now, it…
Endoscope: snoop around inside your Kubernetes pods
Today I ‘released’ endoscope. This is a tool that solves a couple of ‘simple’ problems: I have a running container in Kubernetes. I wish I could have a shell inside it that is root, but also with a bunch of tools like gdb or ptrace. My container doesn’t allow root or ptrace. I don’t want…
Changing the size of a persistent volume in Kubernetes 1.10 on GKE
In Kubernetes v1.11 you can resize persistent volume claims. Great! Sadly, Google has not rolled this out to us great unwashed yet (its available to early-adopters or for everyone on alpha clusters), we are on v1.10. Side note: Docker registry. One of the most commonly asked questions is: how do I delete or clean up?…
My build is slow: understanding resource limits and steal time in the cloudy world of cloud
I earlier wrote about steal time, the concept of “my image wants to use time but its not available due to some unknown noisy neighbour stealing it”. In a nutshell, you have a server with X resources. You then ‘sell’ 10X to your users, making it 10:1 oversubscribed. The Internet industry of late has been…