I once worked for a company that used regular expression matching (pattern matching) on network traffic. A big source of angst was the amount of “unknown traffic”, things which matched no patterns. Our sales team wanted this less. Our customers wanted it less. Our competitors had less. Why couldn’t we?
I used to answer this question as follows. “You know, I can put in one bad pattern, that mis-matches, a false positive. The amount of unknown will go down. Will that make it better? I can make 0% unknown right now.”. Interestingly, some would agree with the statement “sure, lets do that”. Some would say “don’t be ridiculous, I want 100% known, and 0% incorrect.”. I would answer the last question as “what if you made your own proprietary protocol, the license-plate protocol. You, and only you use it. The data in the stream is ciphered from your license plate. Would you expect a pattern for that?”. They would usually say no, I would then point out that 0% unknown as a false goal, the real goal was 0% incorrectly known and as much known as feasible. Still didn’t stop the competitor from using weak false positives to get to higher known amount.
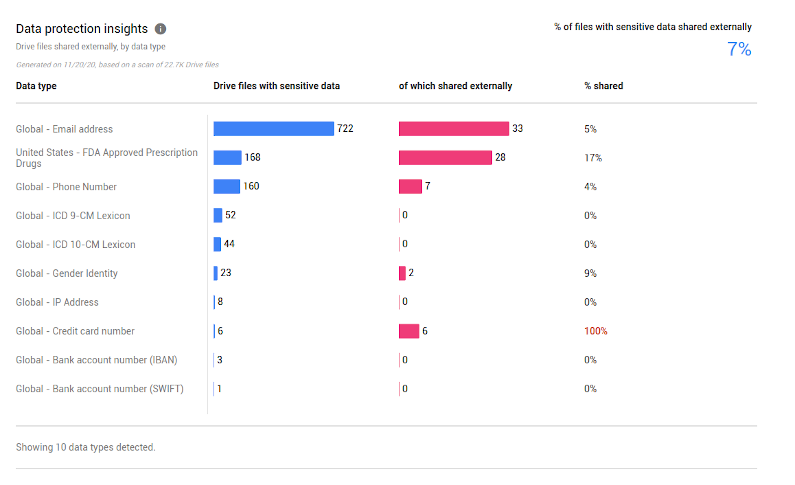
Yesterday I received an email from the good people at Google. They are launching a new document leakage tool. It scans your shared documents for sensitive things (emails, medical, that sort of thing). Mine is below. Its alarming. 7% of my shared files contain sensitive information! O no!
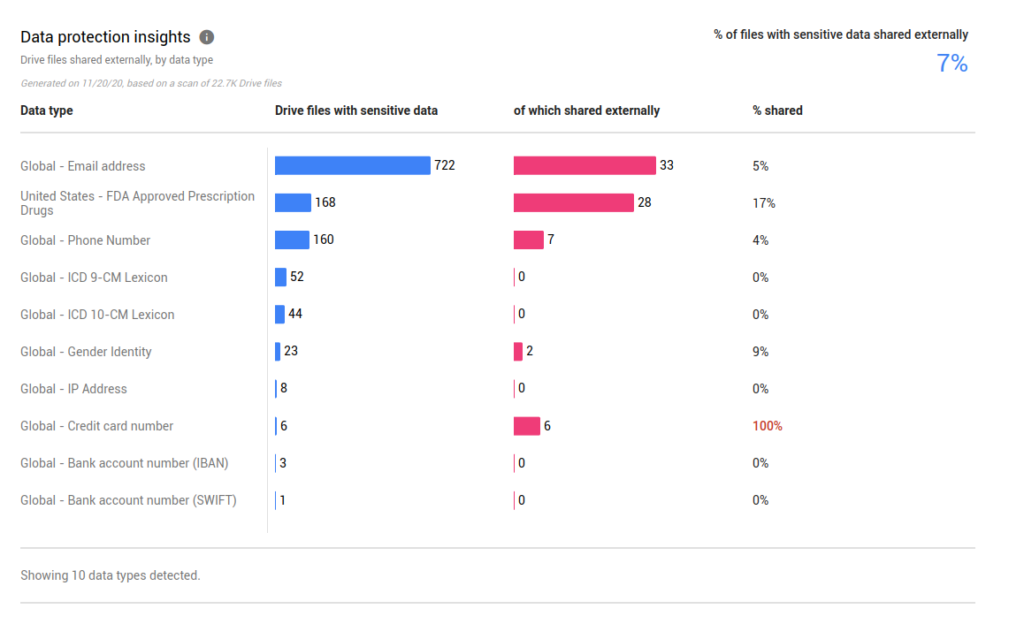
But then I started reading… Its the same pattern match technology. I can guarantee my company deals with 0% “FDA Approved Prescription” information. We also have 0% IBAN and SWIFT and Credit Card Number.
Now, from the report there must be a way to find the offending documents, right? Wrong. You get a number: “9% of your documents shared have Global Gender Identity”. What does that even mean?
This is how you make data untrustworthy and less than useless. I spent time trying to figure out what the call to action was. Eventually I realised the call to action was to ignore: someone at Google has written a few bad regex. They’ve run them on my documents. They’ve shared the categories and counts, but not the links. Their false positive engine cost me time and adds nothing to the universe.
Sadly, I think there are people out there buying pattern engines for all sorts of things, and, pushing towards the false goal of 0% unknown. It must match, right? Wrong.
Leave a Reply