Entropy. Its the clutter on your desk, the noise from your fan, the randomness in your life. We spent most of our lives trying to reduce entropy (filing things, sorting, making order from chaos).
But what if I told you there is an entropy shortage somewhere near you, and, that you should care? Would you come and lock me up in pyjamas with sleeves in the back? Well.. you see, good entropy (randomness) is important for good encryption. And you use a lot of it when you create connections to things (as well as on an ongoing basis). If someone can predict your randomness, even just a little, your protections are reduced.
Enter the cloud. A big server, shared with a lot of people. I’ve even heard terms like ‘serverless’ bandied about for something that looks suspiciously like a server to me, just one that shares with a big pool of the great unwashed.
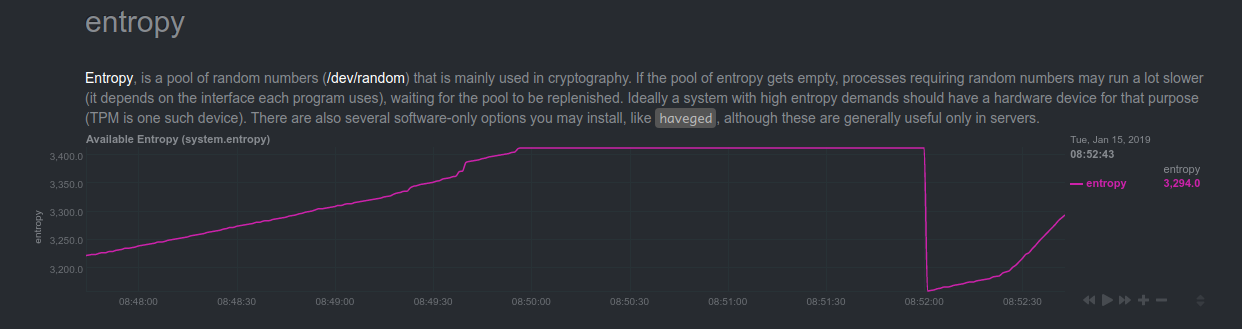
Lets examine the entropy of one of my home Kubernetes system (which has been pressed into service to build envoy which uses bazel which has previously caused a lot of trouble). See the graph? See how it falls off a cliff when the job starts, and then slowly rebuilds? And this is with a hardware-assisted random-number generator (/rngd is reading from /dev/hwrng). Imagine my poor machine trying to collect randomness, where will it get it from? There’s no mouse or keyboard to get randomness from me. It just sits quietly in the basement, same humdrum existence day in and out.
Now, there are usb random number generators (like this one). $100. it generates about 400kbits/s of random. Is it random? Well, that’s a hard test to perform. And it matters. What if its random number generator is like the one in my old TI 99 4/A machine? You called ‘seed(n)’ and it followed a chain.
We could splurge, $300 for this one. Its got 3.2Mb/s of randomness. Maybe I should get a few of these and come up with a cloud service, randomness as a service? O wait, you say that exists?
Leave a Reply