Tag: cloud

The case of the nosy neighbour: Azure is poking me!
We’ve all been there. Working to a deadline trying to get our e-commerce site going to make sure cats don’t get cold feet for the winter. And because its a microservices cloud jwt polyglot kubernetes istio [insert jargon here] world, well, its not as easy to debug. So many moving pieces. Remember when I said…
Pruning elastics with Kubernetes CronJobs
There was a time you just ran ‘crontab -e’ to make this happen. But, progress, are you still on my lawn? Lets discuss how to solve the specific issue of ‘my database fills up my disk’ in a Cloud Native way. So the situation. I’m using ElasticSearch and fluent-bit for some logging in a Kubernetes cluster.…
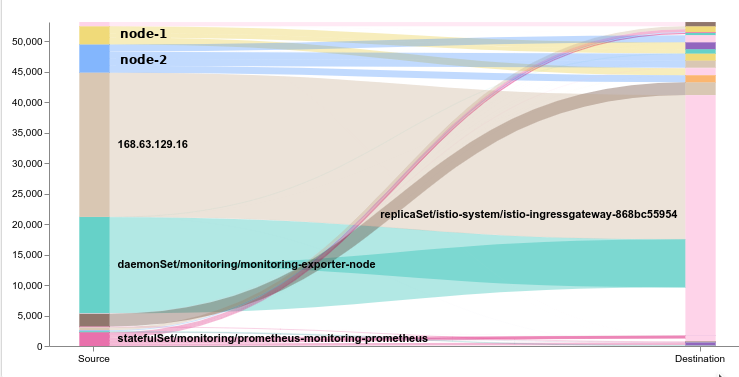
Increasing the usefulness of your Kubernetes Ingress logging
Like most cloud folks you are probably using Kibana + Elasticsearch as part of your log management solution. But did you know with a little regex-fu you can make that logging more interesting? See the kibana expansion in the image, the URI, host, service, etc are all expanded for your reporting pleasure. First, lets install…
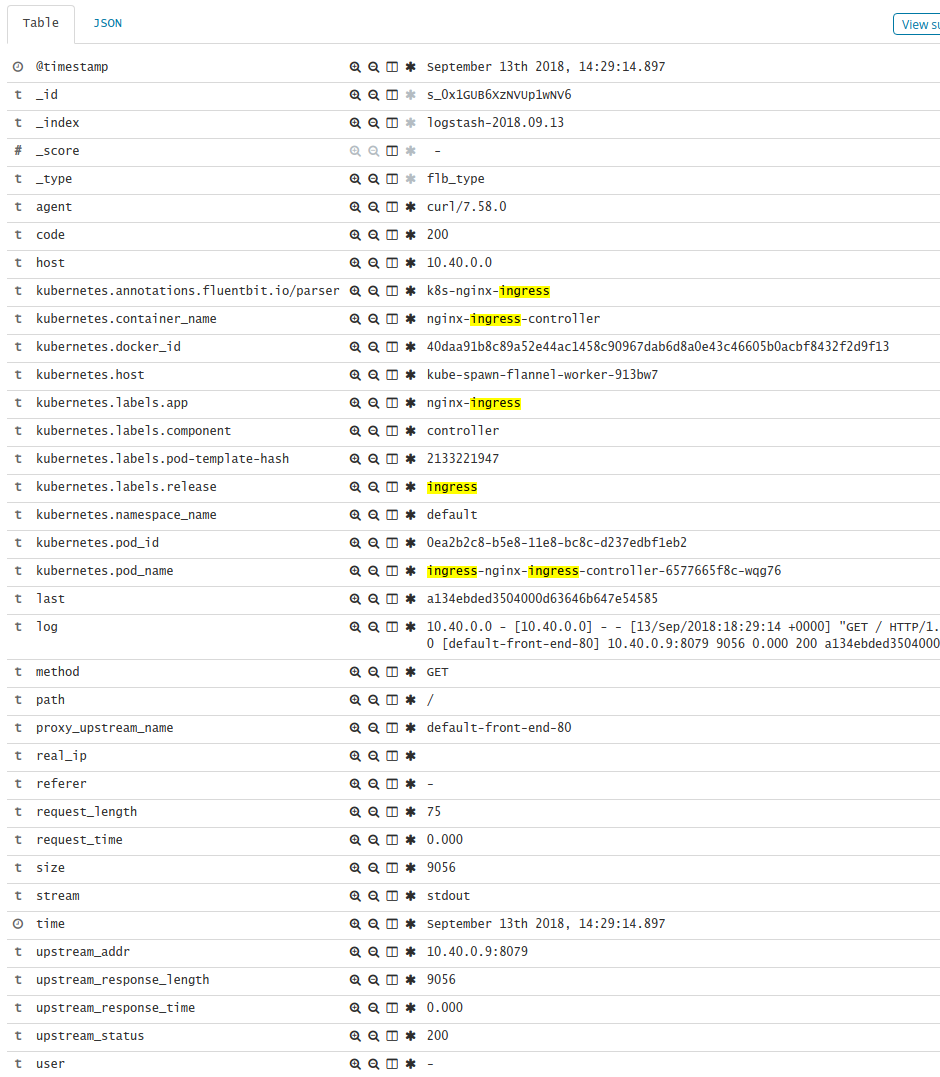
How to avoid being logged, Kubernetes-style
So you have a K8S cluster. Its got a lovely Ingress controller courtesy of helm install stable/nginx-ingress. You’ve spent the last hours getting fluent-bit + elastic + kibana going (the EFK stack). Now you are confident, you slide the user-story to completed and tell all and sundry “well at least when you’re crappy code gets…
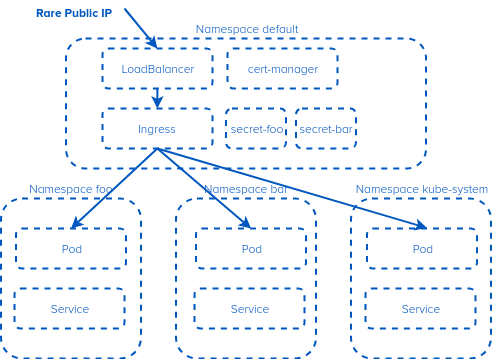
Accessing a service in a different namespace from a single ingress in Kubernetes
IPv4. Its rare when its public, and annoying when its private. So we try and conserve this precious resource. One of the things that makes it complex is Kubernetes namespaces. A Kubernetes Ingress controller is not namespace aware (you can’t have a shared Ingress that has services in multiple namespaces). Or can you? What if…