Tag: cloud

Kubernetes volume-mounts with subPath and inotify. Bah humbug
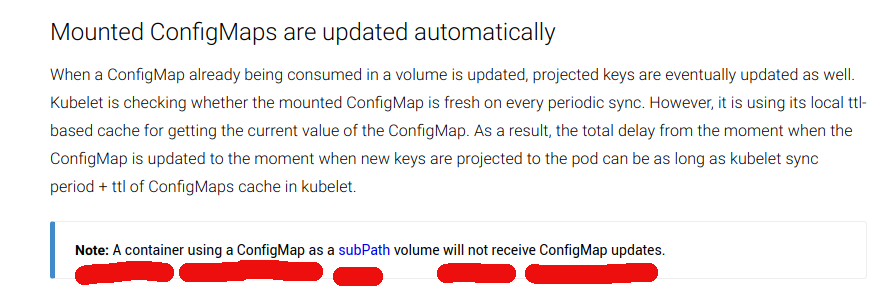
So. I’ve been working on this tool ‘fluent-bit‘. You know the drill. Compile, curse, change, pull-request, repeat. And one of the features I added was to auto-watch its config file and restart on change. This is important in a Kubernetes environment since you supply config via a ‘config map’, and expect it to auto-apply. Great.…
DNS roulette
We’ve all heard of Russian roulette, the game where you take a 6-shooter, put 1 bullet in it, spin it, and point it at your head. I’m hoping this only exists in movies. But what about DNS roulette? Here’s an example. I’m using a web service (Travis) as a CI. And like all good microservices…
Dramatically simplify developing your app for Kubernetes: a sample
Apologies if this is old-hat for you, but, I was awfully tired of ‘git commit; git push; … wait for CI; … helm…’ Lets say you are developing a simple Python flask app. You are going to edit/push many times to get this going perfectly in Kubernetes. So many docker builds and pushes and redeploys…
Kooking Kontainers With Kubernetes: A Recipe for Dual-Stack Deliciousness
If you have a mild allergy to ascii or yaml you might want to avert your eyes. You’ve been warned. Now, lets imagine you have a largish server hanging around, not earning its keep. And on the other hand, you have a desire to run some CI pipelines on it, and think Kubernetes is the…
My webinar today on surprises in cloud security migration
On of the things that people felt was controversial about my message was “end-point security is no longer a thing”. I’m saying this from the standpoint of: Instances are short-lived (hours/days, not months/years) Instances are dynamically scaling in and out Cloud native applications (usually) run a single-process per instance/container, no space for another (you could…